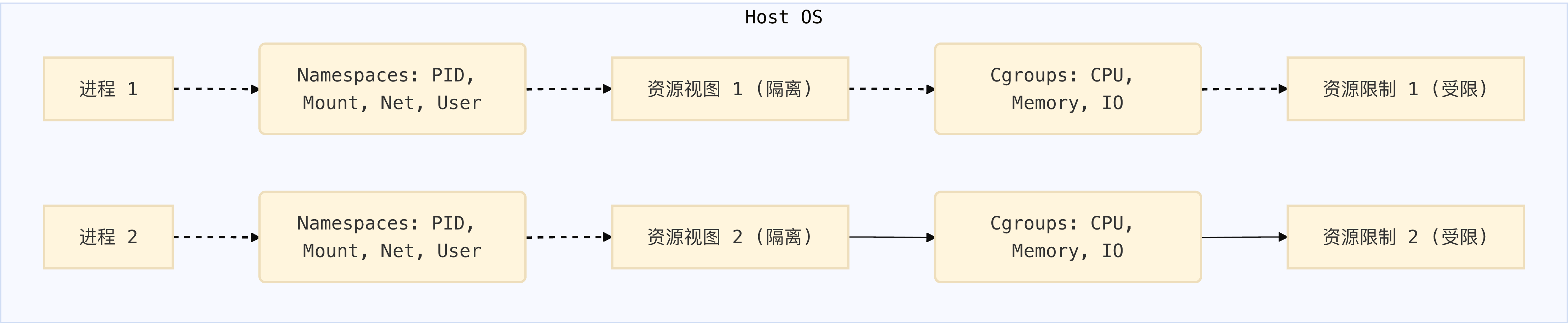
cgroup 管的是“能用多少”,namespace 管的是“能看到什么”,Capabilities:解决“用户能做什么”,seccomp:解决“能调用什么”。
0x01 Namespaces:隔离的魔法
Linux Namespaces 提供了一种将系统资源(如进程ID、网络接口、挂载点等)进行抽象和隔离的机制。这意味着在不同的命名空间中,进程会看到不同的系统资源视图,从而实现了隔离。
常见的Namespaces类型及其隔离内容:
PID Namespace(进程ID命名空间): 隔离进程ID。在新的PID Namespace中,进程会从PID 1开始编号,并且只能看到该Namespace内的进程。外部Namespace的进程看不到内部进程的PID,反之亦然。这是容器内进程拥有独立进程树的关键。Mount Namespace(挂载命名空间): 隔离文件系统挂载点。每个Mount Namespace都有一套独立的挂载点列表。这意味着在一个Namespace内挂载或卸载文件系统,不会影响到其他Namespace。这是容器拥有独立根文件系统的基础。Network Namespace(网络命名空间): 隔离网络资源,包括网络接口、IP地址、路由表、防火墙规则等。每个Network Namespace都有自己独立的网络栈。这是容器拥有独立IP地址和端口空间的基石。UTS Namespace(UNIX Timesharing System命名空间): 隔离主机名和域名。允许每个Namespace拥有独立的主机名和域名。IPC Namespace(Interprocess Communication命名空间): 隔离进程间通信(System V IPC和POSIX消息队列)。User Namespace(用户命名空间): 隔离用户和组ID。允许一个Namespace内的用户ID映射到其外部Namespace的不同用户ID,增强了安全性,例如,容器内的root用户在宿主机上可以是普通用户。
Namespaces的工作原理:
当一个进程在新的Namespace中启动时,它会获得该Namespace的资源视图。例如,当使用unshare命令创建一个新的PID Namespace时,新的shell进程及其子进程将拥有独立的PID空间。
# 查看当前shell pid
echo $$
# 创建一个新的PID Namespace并启动一个子shell
unshare --pid --fork --mount-proc bash
# 查看隔离后的pid 和进程树
root@dev-1-35:/home/u1timate# cho $$
1
root@dev-1-35:/home/u1timate# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 7636 4284 pts/1 S 10:39 0:00 bash
root 7 0.0 0.0 10072 1644 pts/1 R+ 10:40 0:00 ps aux
# 退出新的子shell后,宿主机环境的ps aux又会恢复正常
exitunshare 命令解释
--fork:在新的 Namespace 中启动一个子进程。
--mount-proc:挂载一个新的 /proc,否则你看到的还是宿主机的进程表。
0x02 Cgroups:资源的管家
Linux Cgroups (Control Groups) 提供了一种机制来组织进程,并对其资源使用进行限制、审计和优先级管理。简单来说,Namespaces负责“隔离”,而Cgroups则负责“限制”。
Cgroups的主要功能:
资源限制 (Resource Limiting): 限制进程组可以使用的资源量,例如CPU、内存、I/O带宽等。
优先级 (Prioritization): 调整进程组对资源的访问优先级。
审计 (Accounting): 监控进程组的资源使用情况。
控制 (Control): 挂起或恢复进程组。
常见的Cgroup子系统(Subsystems/Controllers):
cpu: 控制CPU资源访问,例如CPU时间片的分配 (cpu.cfs_quota_us, cpu.cfs_period_us) 和CPU亲和性。memory: 限制内存使用,包括物理内存和交换空间 (memory.limit_in_bytes, memory.memsw.limit_in_bytes)。blkio: 限制块设备(如硬盘)的I/O访问。pids: 限制一个Cgroup内可以创建的进程数量。net_cls / net_prio: 标记网络数据包,以便通过流量控制器(Traffic Controller, TC)进行优先级和带宽管理。
Cgroups的工作原理:
cgroup v1 的管理方式
在
/sys/fs/cgroup/下,每个子系统(CPU、内存、blkio 等)都有独立的层级结构。你可以通过在对应子系统目录下创建子目录来建立新的 cgroup。
配置资源限制时,向该目录下的控制文件写入值,例如
memory.limit_in_bytes。将进程加入 cgroup 时,把 PID 写入 tasks 文件。
cgroup v2 的变化
v2 统一了层级结构:所有控制器共享一个单一的层级,而不是每个子系统独立。
进程管理文件也有所不同:使用
cgroup.procs文件而不是 tasks 文件来添加进程。控制文件的命名和语义也发生了变化,例如 CPU 使用 cpu.weight 而不是 v1 的 cpu.shares。
在大多数现代发行版(如 RHEL 9、Ubuntu 22.04),默认启用的是 cgroup v2。
检查cgroups版本
root@dev-1-35:/home/u1timate# cat /proc/filesystems | grep cgroup
nodev cgroup
nodev cgroup2
# 查看实际正在使用的版本
root@dev-1-35:/home/u1timate# mount | grep cgroup
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
输出包含 cgroup → v1 支持。
输出包含 cgroup2 → v2 支持。
创建一个cgroup(以 v2 版本为例)
# 安装stress工具
sudo apt-get install stress # Debian/Ubuntu
# 创建一个cgroup
mkdir /sys/fs/cgroup/test
# 设置限制
# 设置CPU配额:限制该组进程在100ms内最多使用50ms的CPU时间(即50% CPU)
echo "50000 100000" > /sys/fs/cgroup/test/cpu.maxcpu.max 文件定义了进程在该 cgroup 内可用的 CPU 时间配额。
格式:quota period
quota:允许使用的时间(微秒)。
period:调度周期(微秒)。
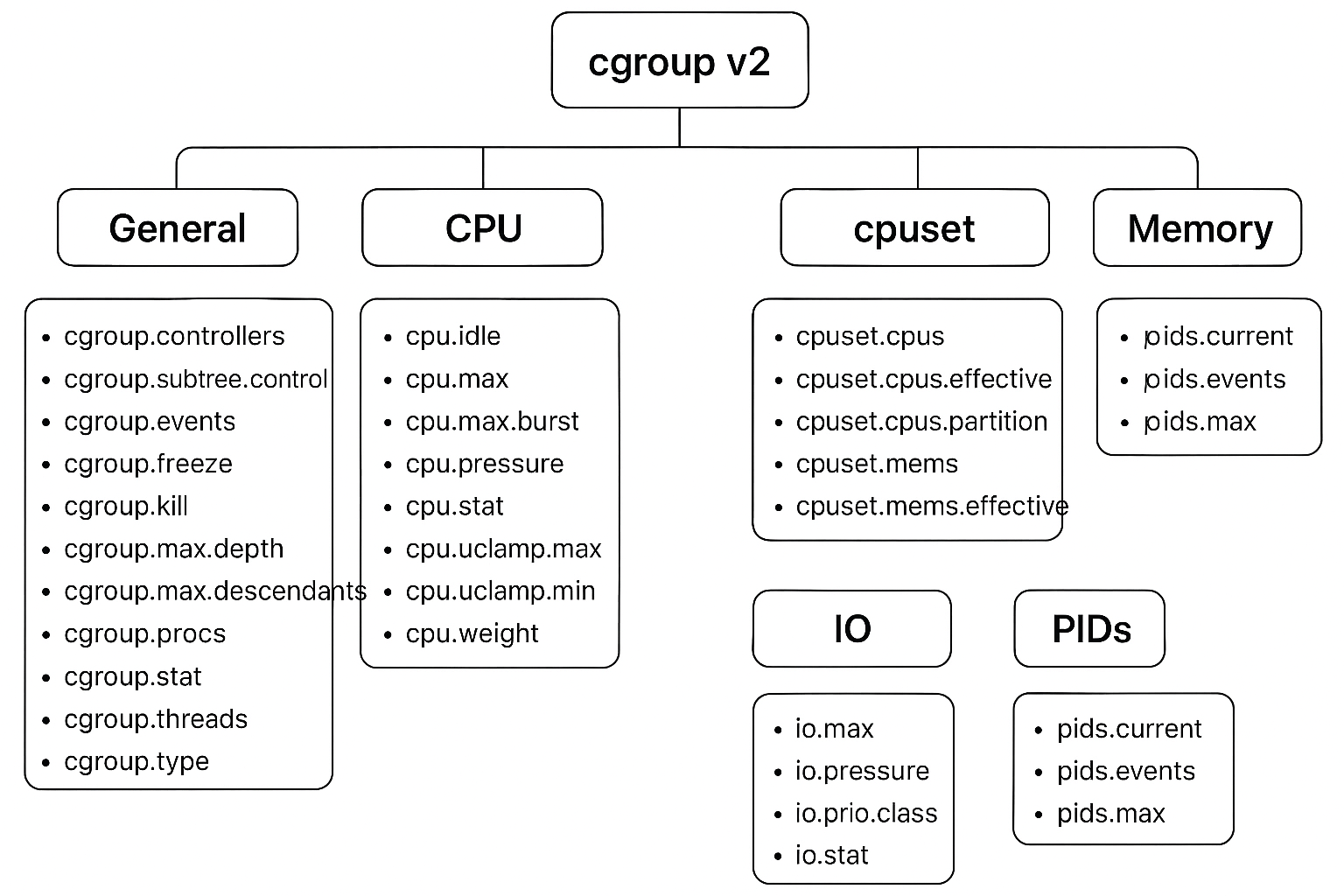
test文件夹下结构:

结构解释:
通用 cgroup 文件
cgroup.controllers:当前层级可用的控制器列表(如 cpu、memory、io 等)。
cgroup.subtree_control:启用/禁用子 cgroup 的控制器。
cgroup.events:记录 cgroup 的事件(如是否被冻结)。
cgroup.freeze:冻结/解冻 cgroup 内的所有进程。
cgroup.kill:终止 cgroup 内的所有进程。
cgroup.max.depth:子 cgroup 最大嵌套深度。
cgroup.max.descendants:子 cgroup 最大数量。
cgroup.procs:该 cgroup 内所有进程的 PID。
cgroup.threads:该 cgroup 内所有线程的 TID。
cgroup.type:cgroup 类型(如 domain、thread)。
cgroup.stat:统计信息(如 nr_descendants、nr_dying_descendants)。
CPU 控制器
cpu.max:CPU 使用配额(quota/period),用于限制 CPU 百分比。
cpu.max.burst:允许的额外突发 CPU 时间。
cpu.weight:CPU 调度权重(相对值,默认 100)。
cpu.weight.nice:与 nice 值对应的权重。
cpu.idle:控制 CPU 空闲时的行为。
cpu.pressure:CPU 压力信息(延迟统计)。
cpu.stat:CPU 使用统计(如 user/system 时间)。
cpu.uclamp.min / cpu.uclamp.max:统一 CPU clamp,限制最小/最大 CPU 性能水平。
CPUSET 控制器
cpuset.cpus:允许使用的 CPU 集合。
cpuset.cpus.effective:实际可用的 CPU 集合(考虑父 cgroup 限制)。
cpuset.cpus.partition:CPU 分区设置。
cpuset.mems:允许使用的内存节点集合。
cpuset.mems.effective:实际可用的内存节点集合。
内存控制器
memory.current:当前内存使用量。
memory.max:最大内存限制。
memory.high:高水位限制,超过时触发回收。
memory.low:低水位保证,尽量保留。
memory.min:最小保证内存。
memory.swap.current:当前 swap 使用量。
memory.swap.max:最大 swap 限制。
memory.swap.high:swap 高水位限制。
memory.swap.events:swap 相关事件统计。
memory.events / memory.events.local:内存事件(如 OOM、high/low 触发)。
memory.pressure:内存压力信息。
memory.oom.group:是否作为 OOM 杀进程的整体。
memory.stat:详细内存统计(anon、file、slab 等)。
memory.numa_stat:按 NUMA 节点的内存使用统计。
IO 控制器
io.max:IO 限制(带宽/IOPS)。
io.weight:IO 权重(相对值)。
io.prio.class:IO 优先级类别。
io.stat:IO 使用统计。
io.pressure:IO 压力信息。
PIDs 控制器
pids.current:当前进程数。
pids.max:最大允许进程数。
pids.events:进程数相关事件(如达到上限)
运行进程测试
限制前:
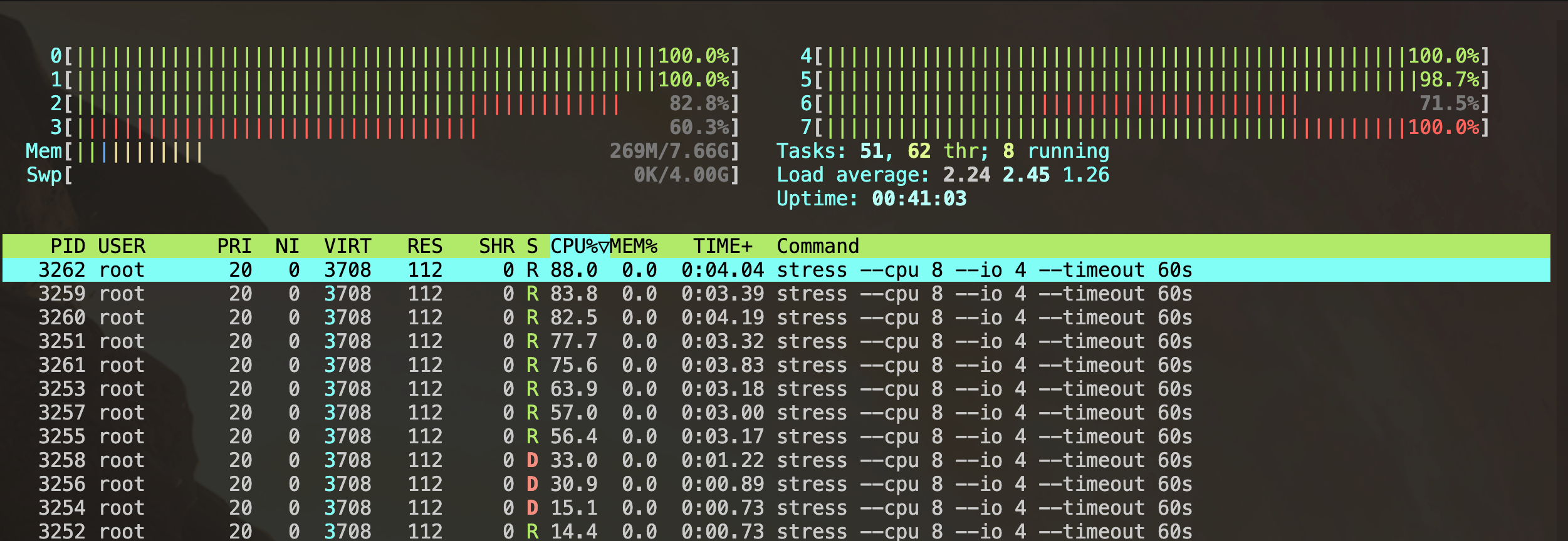
# 使用cgexec将stress命令运行在test中
sudo cgexec -g cpu:test stress -c 8 -t 10s限制后:
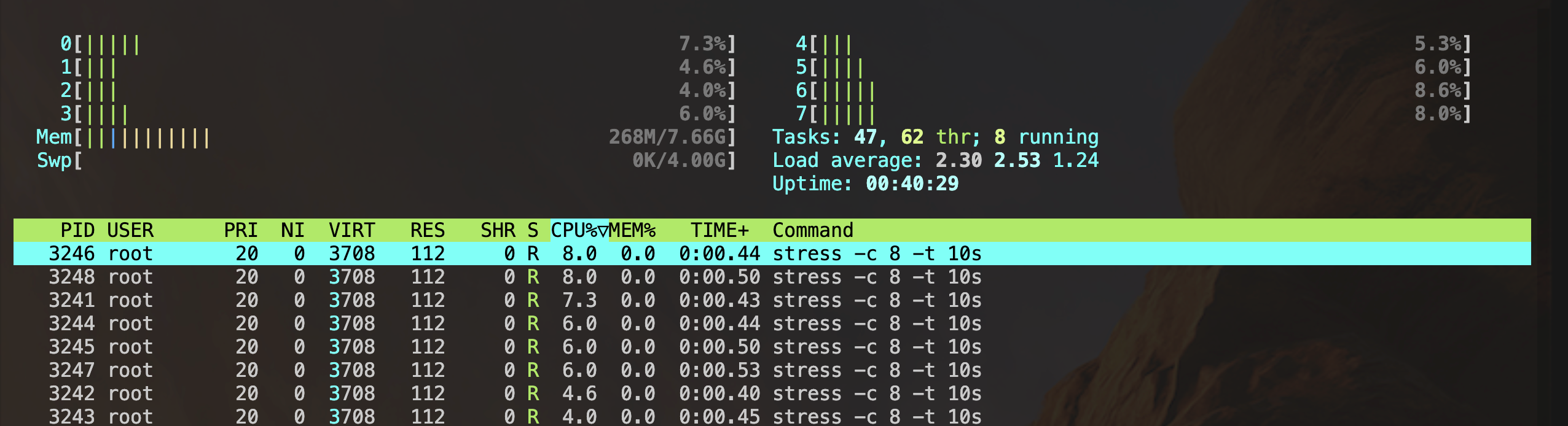
0x03 容器如何利用Cgroups和Namespaces
容器运行时(例如Docker、Containerd)在创建容器时,会执行以下核心步骤:
创建Namespaces: 为新容器进程创建一组新的Namespaces(通常是PID、Mount、Network、UTS、IPC等),使其与宿主机和其他容器隔离。
配置Cgroups: 为容器进程创建一个或多个Cgroups,并根据容器的资源配置(如CPU限制、内存限制)向这些Cgroup的控制文件写入相应的值。
启动进程: 在新创建的Namespaces和Cgroups环境中启动容器的第一个进程。
这样,容器内的进程就拥有了独立的运行环境,并且其资源使用也受到了严格的控制,从而实现了轻量级的、高性能的隔离。
0x04 cgroup v1
文件夹结构
/sys/fs/cgroup/
├── cpu/
│ ├── tasks
│ ├── cgroup.procs
│ ├── cpu.shares
│ ├── cpu.cfs_quota_us
│ └── cpu.cfs_period_us
├── memory/
│ ├── tasks
│ ├── memory.limit_in_bytes
│ ├── memory.usage_in_bytes
│ ├── memory.stat
│ └── memory.failcnt
├── blkio/
│ ├── tasks
│ ├── blkio.weight
│ ├── blkio.throttle.read_bps_device
│ └── blkio.throttle.write_bps_device
├── cpuset/
│ ├── tasks
│ ├── cpuset.cpus
│ ├── cpuset.mems
│ └── cpuset.memory_migrate
├── freezer/
│ ├── tasks
│ └── freezer.state
└── net_cls/
├── tasks
└── net_cls.classid每个控制器(如 cpu, memory, blkio)是一个单独的目录。
每个目录下可以创建子 cgroup(子目录),用于隔离不同进程组。
每个子目录中包含:
tasks:用于写入进程 PID,把它加入该 cgroup。
控制器特有的配置文件(如 cpu.shares, memory.limit_in_bytes)。
你可以通过 mkdir 创建子 cgroup,然后写入配置和 PID 来控制资源。
# 以CPU子系统为例,创建并配置一个Cgroup
# 1. 创建一个名为my_limited_cpu_group的Cgroup
sudo mkdir /sys/fs/cgroup/cpu/my_limited_cpu_group
# 2. 设置CPU配额:限制该组进程在100ms内最多使用50ms的CPU时间(即50% CPU)
sudo sh -c "echo 50000 > /sys/fs/cgroup/cpu/my_limited_cpu_group/cpu.cfs_quota_us"
sudo sh -c "echo 100000 > /sys/fs/cgroup/cpu/my_limited_cpu_group/cpu.cfs_period_us"
# 3. 将当前shell的PID添加到该Cgroup中 (或者使用cgexec)
# 获取当前shell的PID
# echo $$
# 将PID添加到Cgroup的tasks文件中
sudo sh -c "echo $(echo $$) > /sys/fs/cgroup/cpu/my_limited_cpu_group/tasks"
# 4. 运行一个CPU密集型任务(如stress工具),观察其CPU使用率
# 注意:直接运行stress可能需要将其PID移入Cgroup,或者使用cgexec
# 安装stress工具
sudo apt-get install stress # Debian/Ubuntu
# 使用cgexec将stress命令运行在my_limited_cpu_group中
sudo cgexec -g cpu:my_limited_cpu_group stress -c 1 -t 10s
# 观察CPU使用率,会发现stress进程的CPU使用被限制在50%左右
# top # 在另一个终端观察
# 5. 清理Cgroup
sudo rm -rf /sys/fs/cgroup/cpu/my_limited_cpu_group
0x05 Capabilities
Linux 的 Capabilities 是一种“权限细分机制”,它把传统 root 用户的超级权限拆分成多个更细粒度的能力(如修改网络配置、加载内核模块等),从而实现更安全的权限控制。它与 cgroup(资源控制)和 namespace(环境隔离)不同:Capabilities 管的是“用户能做什么”,cgroup 管的是“能用多少”,namespace 管的是“能看到什么”。
在容器场景中需要它来实现:即使容器必须以 Root 运行,我们也要尽可能剥夺它的无关能力(Capabilities),将其破坏力降到最低。
常见能力示例:
CAP_NET_ADMIN:修改网络配置(如设置 IP、路由)。CAP_SYS_ADMIN:系统管理类操作(挂载文件系统、修改内核参数)。CAP_CHOWN:更改文件所有者。CAP_SETUID:修改进程的用户 ID。
运行一个默认特权的容器,并尝试允许网络管理。
root@docker-1-15 ~]# docker run --rm -it alpine ip link add dummy0 type dummy
ip: RTNETLINK answers: Operation not permitte普通容器被剥夺了 CAP_NET_ADMIN 权限。如果你去掉 --cap-add=NET_ADMIN 再次运行上述命令,
docker run --rm -it --cap-add=NET_ADMIN alpine ip link add dummy0 type dummy运行成功。
0x06 Seccomp:系统调用过滤
Capabilities:解决“能做什么”。seccomp:解决“能调用什么”。
Seccomp(Secure Computing mode)是Linux内核提供的一种安全机制,允许进程限制自身可以进行的系统调用。它通过一个可配置的过滤器(基于BPF,Berkeley Packet Filter)来拦截和处理系统调用。当进程尝试执行一个被Seccomp策略禁止的系统调用时,内核可以终止进程、杀死进程或返回错误。
容器运行时(如Docker、containerd)通常会为容器应用默认的Seccomp配置文件,该文件包含了允许和禁止的系统调用列表(比如 keyctl, mount, ptrace)。这有效防止了容器执行一些危险的系统调用,例如直接操作内核模块、修改系统时间等。
参考文件:https://github.com/moby/moby/blob/3bd2edb375af8fab9f6366d57718fcc5561a7d93/contrib/apparmor/template.go#L48 该文件设置容器运行时的系统调用过滤规则,限制容器中可以调用的系统调用 (syscalls),从而增强容器的安全性。
使用默认配置: 大多数情况下,Docker的默认Seccomp配置文件已经足够安全。
最小权限原则: 如果需要自定义,应遵循最小权限原则,只允许容器运行所需的系统调用。
与Capabilities的区别
禁用 seccomp(不推荐)
docker run --rm -it --security-opt seccomp=unconfined alpine0x07 AppArmor:基于路径的强制访问控制
AppArmor(Application Armor)是Linux内核的一个强制访问控制(MAC)系统,它通过将应用程序与一个安全配置文件关联起来,从而限制应用程序的功能。与Seccomp关注系统调用不同,AppArmor关注应用程序对文件、网络、Capabilities等资源的访问。它基于路径(pathname-based)进行访问控制。
AppArmor配置文件定义了应用程序可以做什么,例如:
允许或禁止访问特定文件或目录。
允许或禁止网络操作。
允许或禁止某些Linux Capabilities。
允许或禁止执行其他程序。
与Capabilities的配合
第一道防线 (Capabilities):先剥夺容器的 Root 特权。
如:虽然容器里显示是 root 用户,但我们通过 --cap-drop=ALL 拿走了它的所有特权,只把需要的 CAP_NET_BIND_SERVICE 加回去。这样,就算黑客控制了容器,他也无法修改系统时间或加载内核模块。
第二道防线 (AppArmor):限制容器的文件读写范围。
即使黑客绕过了第一道防线,或者利用了应用本身的逻辑漏洞,AppArmor 也可以阻止他去读取宿主机的 /proc 文件系统,或者阻止他在 /tmp 以外的地方写入恶意脚本。
与Capabilities区别
AppArmor 确实可以控制 Capabilities,而且它在权限检查的链路中确实处于“更后面”的位置(起到一票否决权的作用,它可以推翻前面的允许,但不能推翻前面的拒绝)。并不意味着它能替代 Capabilities。AppArmor控制Capabilities的方式如下
# 禁止使用网络管理能力,即使进程本身拥有这个能力
deny capability net_admin,
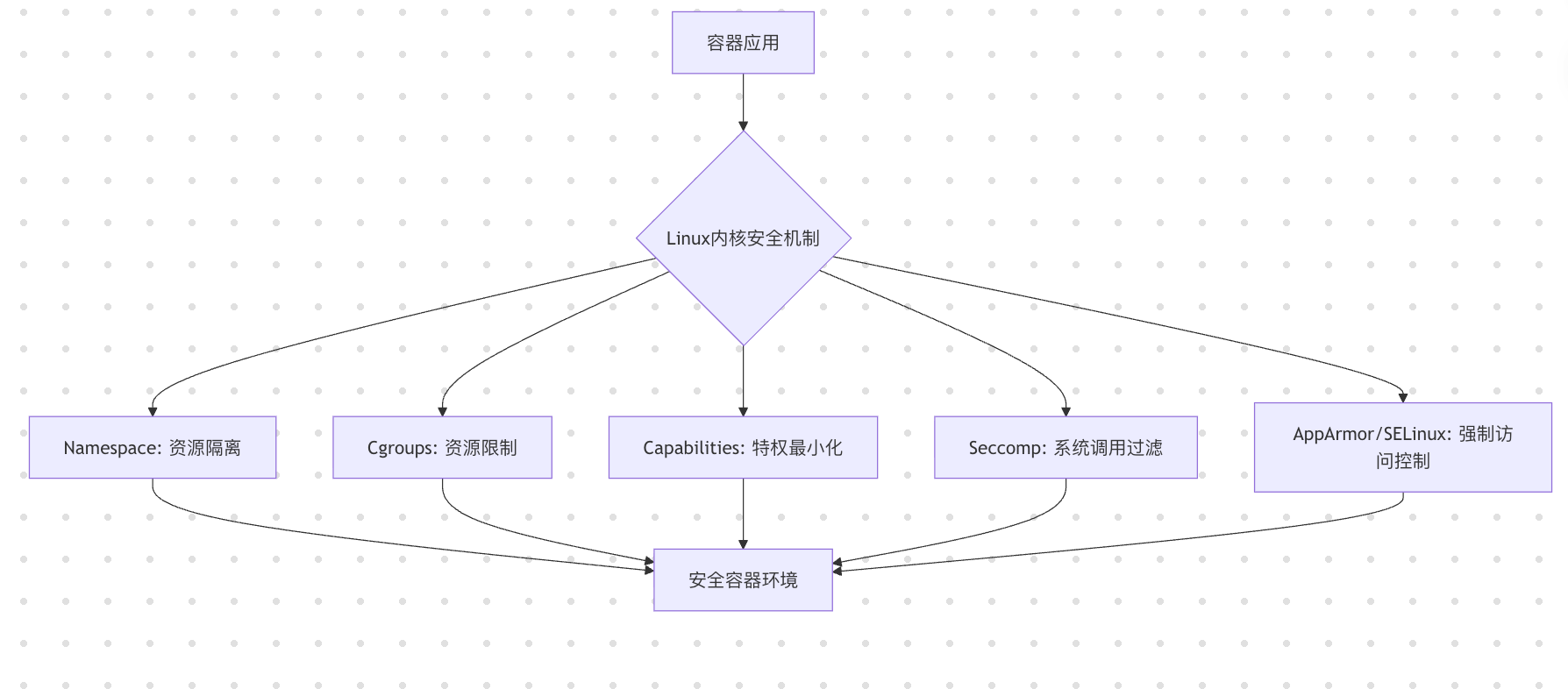
0x08 Linux内核安全机制协同
flowchart TD
A[容器应用] --> B{Linux内核安全机制}
B --> C[Namespace: 资源隔离]
B --> D[Cgroups: 资源限制]
B --> E[Capabilities: 特权最小化]
B --> F[Seccomp: 系统调用过滤]
B --> G[AppArmor/SELinux: 强制访问控制]
C --> H[安全容器环境]
D --> H
E --> H
F --> H
G --> H