
0x01 基于KQL编写规则
KQL:(Kibana Query Language )查询语法是Kibana为了简化ES查询设计的一套简单查询语法,Kibana支持索引字段和语法补全,可以非常方便的查询数据。如果关闭 KQL,Kibana 将使用 Lucene。
KQL仅过滤数据,在汇总,转换或分类数据中没有作用。
KQL不要与具有不同功能集的Lucene查询语言混淆。
常用的查询语句
#获取该字段存在的文档列表
http.request.method: *
# 全文搜索
Hello
# 搜索指定字段的值
# 在查询keyword,数字,日期或布尔字段时,该值必须是确切的匹配,查询文本字段的时候就可以模糊搜索
http.request.body.content: "null pointer"
# 范围搜索
http.response.bytes > 10000 and http.response.bytes <= 20000
@timestamp < now-2w # 参见https://www.elastic.co/guide/en/elasticsearch/reference/8.17/common-options.html#date-math
# 通配符搜索,当前仅支持*
http.response.status_code: 4* # 查找以4开头的文档
# 取反操作
NOT http.request.method: GET # 获取不是Get的文档
# 复杂查询
http.request.method: GET OR http.response.status_code: 400
(http.request.method: GET AND http.response.status_code: 200) OR
(http.request.method: POST AND http.response.status_code: 400)
http.request.method: (GET OR POST OR DELETE) # 速记语法
# 匹配多个字段,前提是这些字段的类型是相同的,否则会报错
datastream.*: logs
# 查询数组,如user:[{first:"", last:""},{}],查询示例如下
user:{ first: "Alice" and last: "White" }0x02 聚合查询
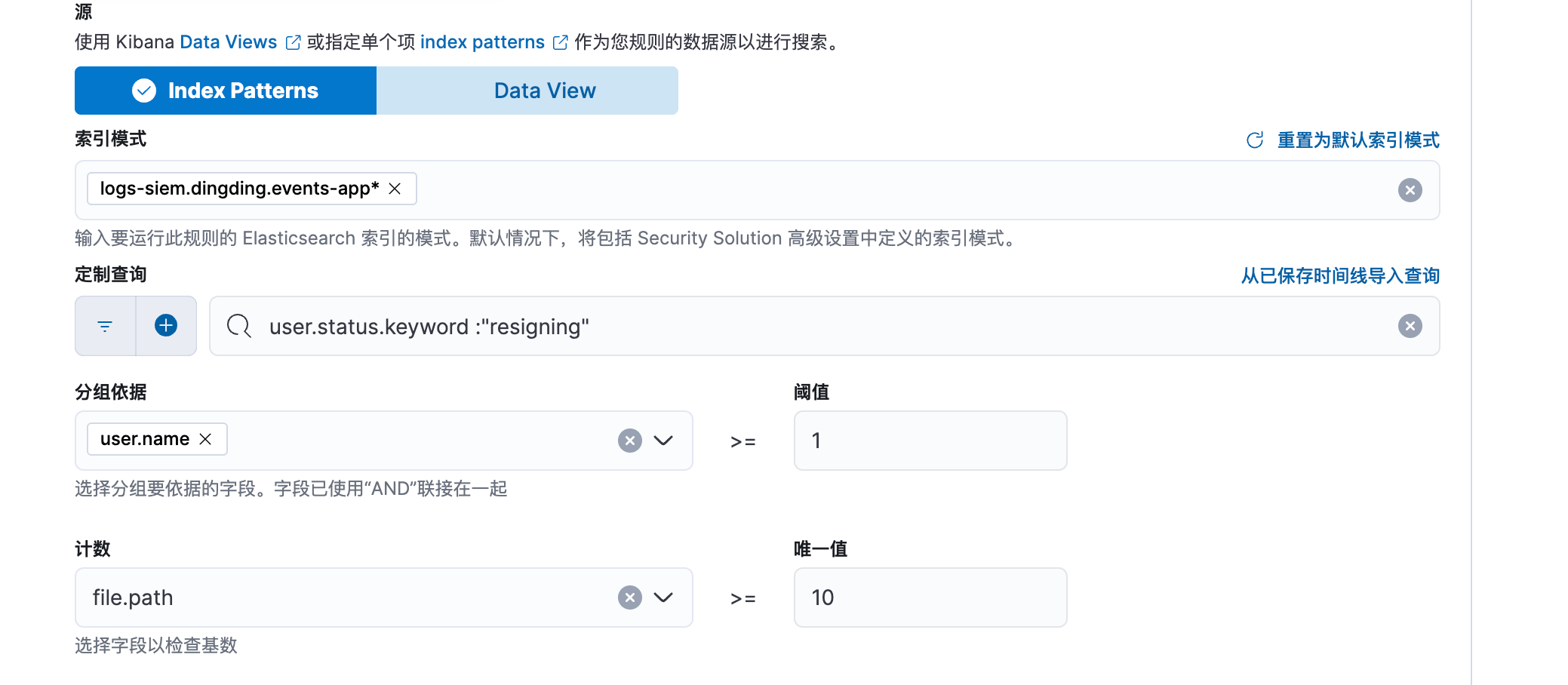
聚合查询结果以检测匹配数目何时超过阈值。
如当钉钉代离职人员操作文件数量大于10的时候,告警
0x03 EQL
Event Query Language (EQL) 是基于事件的时间序列数据的查询语言。在 Elastic Security 平台上,当输入有效的 EQL 时,查询会在数据节点上编译,执行查询并返回结果。这一切都快速、并行地发生,让用户立即看到结果。
EQL syntax reference | Elasticsearch Guide [8.15]
[警告]EQL搜索必须得字段如下:
时间戳@timestamp 字段
event.category 字段
没有这些字段,在XDR中编写EQL规则,会报错
语法简介
event_category where condition # event_category 默认使用ECS标准的event.category,如果event_category为any的情况下,表示匹配任意事件类型如果需要替换需要在API中设置event_category_field的值,如下
GET /my-data-stream/_eql/search
{
"timestamp_field": "file.accessed",
"event_category_field": "file.type", # 这里就将类型字段修改file.type了
"query": """
file where (file.size > 1 and file.type == "file")
"""
}查询示例
event.category为process, 且process.name为regsvr32.exe的文档
{
"query": """
process where process.name == "regsvr32.exe"
"""
}默认情况下会返回10个文档,且根据时间升序排列。
{
"query": """
process where process.name == "regsvr32.exe"
""",
"size": 50 # 指定返回的文档数量
}匹配任意类型的事件
any where process.name == "regsvr32.exe"注意:如果字段包含-,以数字开头,包含空格的情况,需要包裹,如process name` == "regsvr32.exe"
匹配指定事件的任意条件
process where true正则表达式
my_field like "VALUE*" // 大小写敏感的模糊匹配,以VALUE开头,如果是?表示只匹配一个
my_field like "VALUE?" //大小写敏感的模糊匹配,以VALUE开头,匹配长度为1,比如VALUES匹配成功,VALUESS匹配失败
my_field like~ "value*" //大小写不敏感的模糊匹配
my_field regex "VALUE[^Z].?" // 大小写敏感的正则匹配
my_field regex~ "value[^z].?" // 大小写不敏感的正则匹配比较的局限性
EQL是不支持链式比较的,也不支持两个字段进行直接比较,比如
0<file.count<10
process where process.parent.name == "foo" and process.parent.name == process.name 应该换成这样
file.count<10 and file.count>0
process where process.parent.name == "foo" and process.name == "foo"查询操作符
my_field in ("Value-1", "VALUE2", "VAL3") // case-sensitive
my_field in~ ("value-1", "value2", "val3") // case-insensitive
my_field not in ("Value-1", "VALUE2", "VAL3") // case-sensitive
my_field not in~ ("value-1", "value2", "val3") // case-insensitive
my_field : ("value-1", "value2", "val3") // case-insensitive,仅支持字符串比较
my_field like ("Value-*", "VALUE2", "VAL?") // case-sensitive
my_field like~ ("value-*", "value2", "val?") // case-insensitive
my_field regex ("[vV]alue-[0-9]", "VALUE[^2].?", "VAL3") // case-sensitive
my_field regex~ ("value-[0-9]", "value[^2].?", "val3") // case-insensitive字段是否存在
?my_field != null # my_field这个字段存在
?my_field != null # my_filed这个字段不存在[旗子]Sequence时序
时序数据是按时间排序的、具有明确时间戳的事件记录,例如日志、监控数据和事务数据。可以做事件关联
时序匹配方式
基础查询: 匹配所有符合条件的单个事件。
process where process.name == "regsvr32.exe"上述查询会筛选所有进程名为 regsvr32.exe 的事件。
事件序列匹配 (sequence): 按时间顺序寻找一组相关事件。
sequence
[ process where process.name == "regsvr32.exe" ]
[ file where file.name == "scrobj.dll" ]匹配一个进程 regsvr32.exe 和文件 scrobj.dll 的创建,要求事件发生顺序符合书写顺序。
时间约束 (maxspan): 为事件序列的发生时间添加约束,例如必须在 1 小时内完成:
sequence with maxspan=1h
[ process where process.name == "regsvr32.exe" ]
[ file where file.name == "scrobj.dll" ]缺失事件 (!): 匹配不包含某些条件的操作,例如:
sequence
[ process where process.name == "cmd.exe" ]
![ process where process.command_line contains "ocx" ]
[ file where file.name == "important.log" ]在执行 cmd.exe 后,没有执行包含 ocx 的命令行动作,却最后创建了 important.log 文件。
by关键字
by 关键字是用于 按字段值分组 的方式,确保序列中的事件是关联的,并且字段值是共享的。确保匹配结果属于同一个逻辑上下文(如用户、进程、主机等)。例如:
按相同的用户分组。
按同一进程分组。
按设备或 IP 地址分组。
sequence
[ file where file.extension == "exe" ] by user.name, file.path
[ process where true ] by user.name, process.executable查询逻辑中要求事件按时间顺序出现:
1、第一个事件匹配 file.extension == "exe" 且分组字段值满足一致性(相同用户(user.name)且使用相同文件路径(file.path)的事件)。
2、与第一个事件相同用户(user.name)且运行相同可执行文件路径(process.executable)的所有process事件会被命中
sequence by process.pid
[ process where process.name == "cmd.exe" ]
[ file where file.name == "important.txt" ]在事件流中,找到进程 ID (process.pid) 相同的事件,并且必须按顺序满足以下条件:
名为
cmd.exe的进程。该进程操作了名为
important.txt的文件。
典型场景的适用性:
文件-进程链式关联(恶意文件运行)。
用户操作追踪(监控用户对敏感文件的交互)。
功能扩展场景(加入 maxspan 限定时间范围等)。
until关键字
用于指定事件序列的终止条件。换句话说,当 sequence 查询匹配到 until 所定义的特定事件时,序列的追踪会提前终止,而不会继续寻找后续的事件。
基本语法
sequence
[ event_type_1 where condition_1 ]
[ event_type_2 where condition_2 ]
...
until
[ event_type_termination where termination_condition ]使用示例
sequence by process.pid
[ process where process.name == "notepad.exe" ]
[ file where file.extension == "txt" ]
until
[ process where event.action == "termination" ]查找名称为 notepad.exe 的进程。找到该进程后,如果它与 .txt 文件发生交互,事件符合序列。直到如果检测到此进程的终止事件(event.action == "termination"),查询将停止进一步追踪。
适用的场景:
进程行为终止:
只追踪进程在正常运行期间的事件,忽略进程终止后的事件。
示例:分析恶意软件运行前的行为链。
网络连接状态终止:
若网络连接被关闭,停止追踪连接的所有后续事件。
示例:追踪数据泄露或异常连接。
用户登录/登出行为链:
当用户退出时,不再追踪该用户的行为。
示例:分析用户的高危操作,直到用户主动退出为止。
对象操作终止:
文件、资源或设备被删除时停止追踪后续操作
示例:追踪被修改的文件,直到文件被删除为止。
with run 语法
用于将事件序列的匹配与 数据分组 或 次数统计 相结合。它可以帮助我们实现特定上下文下的批量匹配,从而有效地表达 重复行为 的查询逻辑。
将一个或多个源事件序列在分组基础上进行匹配,并验证其是否满足预期的重复次数。可结合统计行为场景,例如:某用户多次登录失败后,再查看关键数据文件。
sequence with runs=次数条件
[ event_type_1 where condition_1 ]
[ event_type_2 where condition_2 ]runs:指定序列在分组条件(如按用户分组)下匹配的次数限制,例如 runs=5 代表该序列必须重复发生 5 次。
示例:
sequence with runs=5 by user.name
[ authentication where event.type == "login" and status == "failed" ]同一用户是否尝试登录超过了5次
sequence
[ process where event.type == "creation" ] by process.executable
[ library where process.name == "regsvr32.exe" ] by dll.path with runs=3这段查询会查找以下两个逻辑上相关的事件序列:
事件 1:某个进程可执行文件(例如 malicious.exe)的 创建操作。
事件 2:与该进程相关联的 regsvr32.exe 连续加载3 次相同 DLL 文件 的行为。
使用场景
入侵检测: 例如检测恶意软件活动:
sequence
[ process where process.name == "powershell.exe" ]
[ network where network.direction == "outbound" and network.name == "malicious_server.com" ]此查询查找通过 PowerShell 到外部恶意服务器的网络连接。
异常行为监控: 检测系统中的异常登录行为:
sequence with maxspan=10m
[ authentication where user.name == "admin" and event.type == "successful" ]
[ authentication where user.name == "admin" and event.type == "failed" ]查询管理员在 10 分钟内成功登录后立即尝试失败登录。
检测特定用户的行为链
sequence by user.name
[ authentication where event.type == "login" and result == "success" ]
[ process where process.name == "powershell.exe" ]
[ network where network.direction == "outbound" and destination.ip == "192.168.0.100" ]匹配同一个用户名 (user.name) 下按照时间顺序发生的事件链:
1、成功登录。
2、使用 PowerShell 运行命令。
3、执行了 outbound 网络连接到 IP 地址 192.168.0.100。
限时重复行为
sequence with runs=5 by user.name with maxspan=30m
[ authentication where event.type == "login" and status == "failed" ]匹配在 30 分钟内,用户登录失败事件必须重复出现至少 5 次。
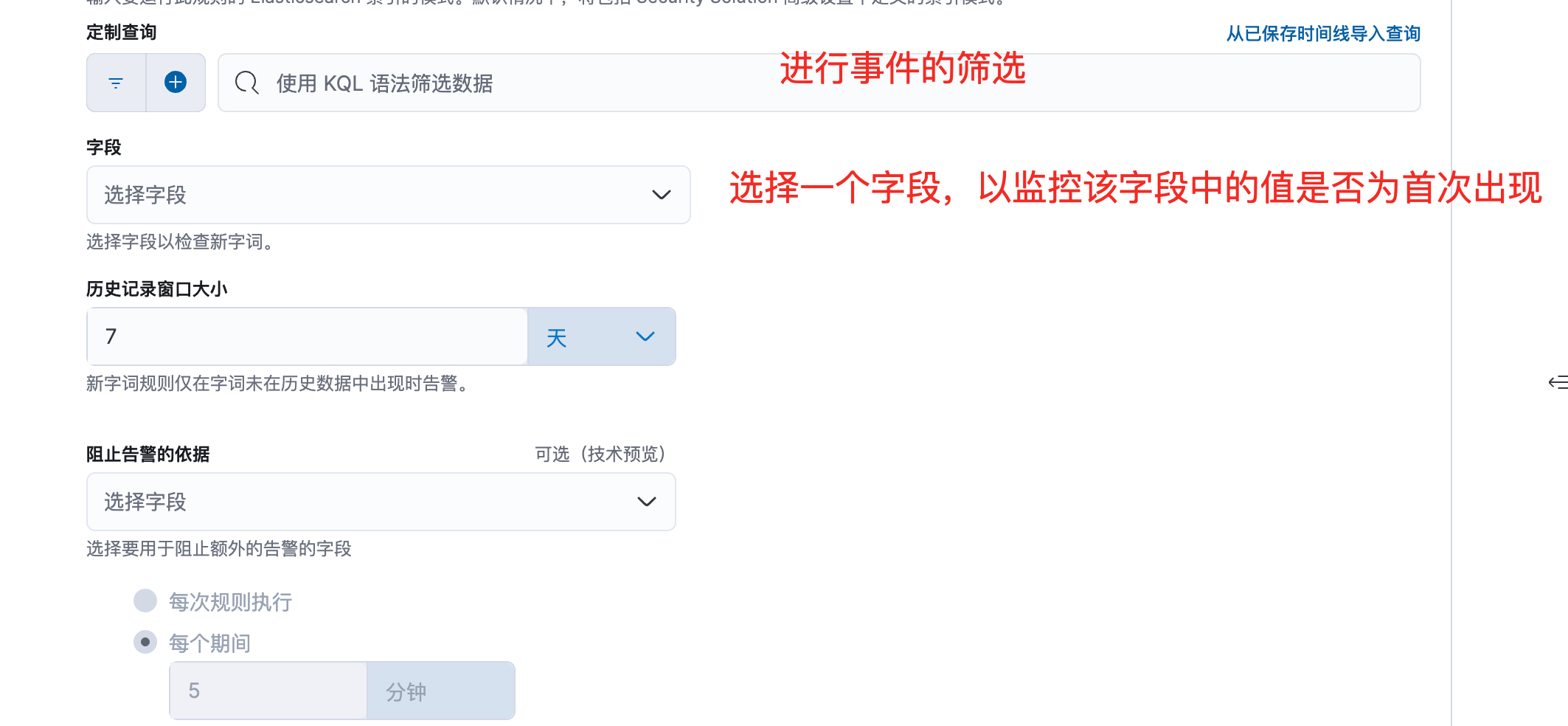
0x04 新字词
0x05 ES|QL
https://www.elastic.co/guide/en/elasticsearch/reference/8.15/esql-getting-started.html
ES|QL (Elasticsearch Query Language) 是一种新型的基于管道 (piped) 的查询语言,这种语言旨在简化对数据的查询、转换、聚合和可视化流程。它是一种高级查询语言,提供了比传统 Elasticsearch Query DSL 更加直观和功能丰富的写法,专用于复杂数据查询和探索。
核心功能
查询数据:通过指定数据源
(from <index>)快速查询所需数据。数据转换:支持基于字段的动态计算 (
eval)、数据过滤 (where)、储存或处理表操作。数据聚合:支持统计、分组、排序等操作,类似 SQL 的操作方式。
数据集关联:可以通过 enrich 功能在不同数据表之间建立关联,丰富数据内容。
可视化:与 Elasticsearch 内的可视化工具(如 Kibana)高度集成,有助于用户对查询结果进行直观展示。
ES|QL 的语法采用管道 (|) 表示连续步骤,结合了 SQL 的部分结构化语言风格,适合数据流水线的逐步处理。示例如下:
from logs-*
| stats avg_bytes = avg(bytes) by user.name
| eval avg_kb = avg_bytes / 1024
| sort avg_kb desc
| limit 5从 logs-* 索引中查询数据。然后计算每位用户的数据传输平均值并转换为 KB。最后按降序排列并仅显示前 5 条记录。
任何一条ES|QL语句都是从from这种源命令开始, 这种命令将es中的文档转成一个表格,表格的每一行都代表一个文档,如下
后续在针对这个表格通过管道符方式进行操作。示例如下:
from logs-siem.dingding.events-app-2025.03 | LIMIT 3 # 只获取表格的前三行
FROM logs-siem.dingding.events-app-2025.03 | SORT @timestamp DESC # 安装指定的指定进行排序
FROM logs-siem.dingding.events-app-2025.03
| WHERE file.size > 5000000链式命令处理
可以链式编写命令,并由管道字符|隔开。每个处理命令都可以在上一个命令的输出表上工作。查询的结果是最终处理命令产生的表。示例如下
FROM sample_data
| SORT @timestamp DESC
| LIMIT 3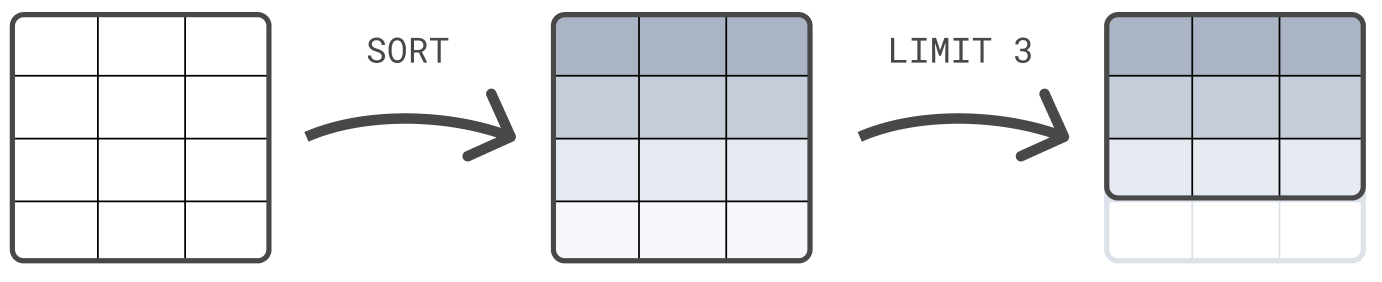
eval 命令
主要用于动态计算字段值或创建新字段。它允许我们对现有的数据进行转换、计算,甚至生成衍生的字段,而无需预先在索引映射中定义。
语法如下:
eval new_field = expressionexpression:计算表达式,包含常规运算(加减乘除、比较等)、字符串函数、日期时间函数、类型转换函数,以及其他内置函数。
FROM sample_data
| EVAL duration_ms = ROUND(event_duration/1000000.0, 1)stats 数据汇总
用于对数据进行聚合统计并按指定字段分组。它类似于 SQL 中的 GROUP BY 操作。基本语法如下
STATS [统计函数(field)] AS new_field [BY group_field, ...]统计函数:对数据字段执行聚合操作,例如
count(),sum(),avg(),max(),min()等。AS new_field:可以为统计结果指定一个输出字段名。
BY group_field:按一个或多个字段进行分组。
示例如下:
计算事件数量
FROM logs-siem.dingding.events-app-2025.03
| STATS login_count = COUNT() by user.full_name
| sort login_count DESC按 user.full_name 分组。统计每位用户的事件数量,生成字段 login_count。最后按登录事件数量降序排序。
ENRICH命令
用于丰富(扩展)数据,通过将主数据集中的记录与外部数据源(索引)连接起来,动态地补充字段信息。这类似于 SQL 中的 JOIN,但更灵活,专门用于基于 Elasticsearch 索引进行跨数据集的关联查询。
语法如下:
ENRICH <target_index> ON <match_field> WITH <additional_fields><target_index>:需要 enrich 的目标索引。<match_field>:主数据集字段与目标索引字段间的匹配条件。<additional_fields>:从目标索引中提取的额外的字段列表,用于丰富主数据集。
注意:ENRICH 命令依赖 Elasticsearch 中提前配置的 enrich policy。使用如下接口查看现有的 enrich policies
GET /_enrich/policy
{
"policies": []
}如果没有enrich policy 需要手动配置
创建enrich policy策略
创建策略
PUT /_enrich/policy/resigning-employee
{
"match": {
"indices": ["resigning-employee-*"],
"match_field": "user.id",
"enrich_fields": ["status"]
}
}indices:指定目标索引(例如resigning-employee-*)。match_field:设置匹配字段,例如client_ip。enrich_fields:设置需要添加到主数据集中的字段。
执行策略生成enrich index
注意:每次向索引之后添加玩数据后都要运行下面的接口,因为Enrich Index 是根据 Enrich Policy 手动执行后一次性生成的,而不是动态同步的
POST /_enrich/policy/resigning-employee/_execute检查用户角色
用户运行 ENRICH 查询需要具备以下权限:
读取政策索引的权限 (read index)。
enrich_user 角色权限:这是 Elasticsearch 内置角色,提供 enrich 相关操作的权限。
GET /_security/user删除策略
DELETE /_enrich/policy/resigning-employee
{
"acknowledged": true
}示例
FROM sample_data
| KEEP @timestamp, client_ip, event_duration
| EVAL client_ip = TO_STRING(client_ip)
| ENRICH clientip_policy ON client_ip WITH env
| STATS median_duration = MEDIAN(event_duration) BY env分解:
KEEP @timestamp, client_ip, event_duration 保留字段 @timestamp, client_ip, 和 event_duration,丢弃其他不相关字段。
EVAL client_ip = TO_STRING(client_ip) 将字段 client_ip 转换为 字符串类型,确保其格式正确以用于后续 ENRICH 关联。
ENRICH clientip_policy ON client_ip WITH env使用主数据集的 client_ip 字段与 clientip_policy 索引中的 client_ip 字段匹配。匹配成功后,从 clientip_policy 提取字段 env
STATS median_duration = MEDIAN(event_duration) BY env 按 env 字段分组,即每个环境(例如 test, production, development 等)形成一个独立分组。在每个分组内,计算字段 event_duration 的中位值,生成新字段 median_duration。
查询结果示例如下:
//sample_data索引
[
{ "@timestamp": "2023-03-14T10:00:00Z", "client_ip": "192.168.1.1", "event_duration": 200 },
{ "@timestamp": "2023-03-14T10:05:00Z", "client_ip": "192.168.1.1", "event_duration": 300 },
{ "@timestamp": "2023-03-14T10:10:00Z", "client_ip": "192.168.1.2", "event_duration": 150 },
{ "@timestamp": "2023-03-14T10:15:00Z", "client_ip": "192.168.1.3", "event_duration": 400 }
]
//clientip_policy 索引
[
{ "client_ip": "192.168.1.1", "env": "production" },
{ "client_ip": "192.168.1.2", "env": "staging" },
{ "client_ip": "192.168.1.3", "env": "development" }
]
//查询结果
[
{ "env": "production", "median_duration": 250 },
{ "env": "staging", "median_duration": 150 },
{ "env": "development", "median_duration": 400 }
]示例场景
检测暴力登录尝试
FROM logs-siem.mailsec.events-app-*
| where event.action == "smtp-login" and event.outcome=="failure"
| STATS fail_count=COUNT() by user.email
| where fail_count>5
| keep user.email, fail_count从
logs-siem.mailsec.events-app-*中筛选出所有登录失败的记录。按用户名 (
user.email) 分组,统计每个用户的失败尝试次数。筛选失败次数大于 5 的用户,称为异常行为。
返回触发条件的用户名和失败次数。
待离职用户下载文件
注意使用ENRICH的时候,要确定已经创建了resigning-employee策略
FROM logs-siem.dingding.events-app-*
| ENRICH resigning-employee ON user.id WITH status
| where status=="resigning"
| STATS download_count=COUNT() by user.id
| where download_count>10
| KEEP user.id, download_count,status使用
ENRICH命令,从名为 resigning-employee的enrich policy索引中补充员工信息。按user.id进行匹配,将enrich policy中的 status 字段动态附加到主数据集。筛选出
status为 "resigning" 的记录,仅关注即将离职的员工。按员工 (user.id) 作为分组字段,对每位员工的日志事件进行统计。对于每个员工,统计其下载次数 (
COUNT()),生成一个新字段download_count,表示员工下载文件的总次数。将文件下载次数超过 10 次的离职员工记录筛选出来。这些员工可能存在异常数据访问行为。
仅保留用户 ID (user.id)、文件下载次数 (
download_count)、员工状态 (status)。剔除其他无关字段。
检测恶意文件访问
FROM file-access-logs
| WHERE file.name == "config.json" OR file.name == "db_backup.sql"
| STATS access_count = COUNT() BY user.name, file.name
| WHERE access_count > 10
| KEEP user.name, file.name, access_count筛选出访问目标文件(如 config.json 或 db_backup.sql)的所有记录。
按用户名 (user.name) 和文件名 (file.name) 分组。
统计用户对特定文件的访问次数 (COUNT)。
筛选访问次数超过 10 的记录,认为是异常行为。
返回用户名、文件名和访问次数。
结合威胁情报库
FROM network-logs
| ENRICH threat-intel-db ON source.ip WITH threat.level, threat.category
| WHERE threat.level >= 5
| STATS attack_count = COUNT() BY source.ip, threat.category
| KEEP source.ip, threat.category, attack_count使用 ENRICH 将主日志的 IP (source.ip) 与威胁情报数据库 (threat-intel-db) 动态关联。
提取威胁等级 (threat.level) 和威胁类别 (threat.category)。
筛选高威胁等级的记录(threat.level >= 5)。
按来源 IP 和威胁类别分组,统计攻击次数。